I’ve got a table that has rows that are unique except for one value in one column (let’s call it ‘Name’). Another column is ‘Date’ which is the date it was added to the database.
What I want to do is find the duplicate values in ‘Name’, and then delete the ones with the oldest dates in ‘Date’, leaving the most recent one.
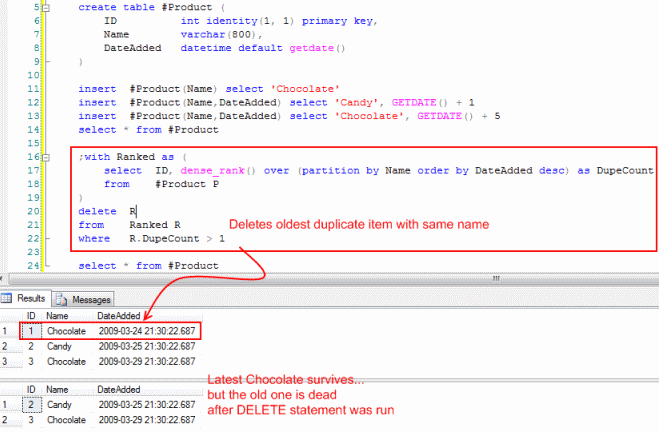
create table #Product (
ID int identity(1, 1) primary key,
Name varchar(800),
DateAdded datetime default getdate()
)
insert #Product(Name) select 'Chocolate'
insert #Product(Name,DateAdded) select 'Candy', GETDATE() + 1
insert #Product(Name,DateAdded) select 'Chocolate', GETDATE() + 5
select * from #Product
;with Ranked as (
select ID,
dense_rank()
over (partition by Name order by DateAdded desc) as DupeCount
from #Product P
)
delete R
from Ranked R
where R.DupeCount > 1
select * from #Product
This website uses cookies to improve your experience. We\'ll assume you\'re ok with this, but you can opt-out if you wish.
Read More
Cookies are small text files that can be used by websites to make a user\'s experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies we need your permission. This site uses different types of cookies. Some cookies are placed by third party services that appear on our pages.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.